Appearance
概述
- 基本思路: 高可用(High Availability,HA)的主要目标是通过冗余方式保证服务不中断。常见做法是分配一个虚拟 IP(VIP),让外部 DNS 解析到该 VIP,再由内部的高可用软件(如 keepalived)根据节点状态决定哪个节点负责接管流量。
原理
VRRP 协议:
- **背景:** VRRP(Virtual Router Redundancy Protocol)最初用于网络设备之间的冗余备份。
- **实现:** keepalived 基于 VRRP 实现高可用,即主备两个节点间通过发送心跳包来确认对方的存活状态。
工作机制:
- 主节点(MASTER)定期向备节点发送 VRRP 数据包,表示自身正常运行。
- 如果备节点长时间未收到心跳,则判断主节点已经挂掉,进而切换成为新的主节点,并接管 VIP。
- **注意事项:** 数据包是通过组播(如 224.xx.xx.xx)发送的。
极速上手指南
安装与配置:
安装: 通过 yum install -y keepalived 安装高可用软件。
配置文件结构: /etc/keepalived/keepalived.conf 的配置格式,主要分为三个部分:
- global_defs(全局定义): 用于定义全局参数,如
router_id,保证当前网络中每个节点的唯一性。
****:
+ 配置 VIP、状态(MASTER 或 BACKUP)、网络接口、虚拟路由器 ID、优先级(数字越大优先级越高)和心跳间隔(advert_int)。
+ 配置认证参数(auth_type 和 auth_pass)来确保数据包的安全性。
+ 配置 VIP 地址,如设置为 `10.0.0.3` 并指定对应网卡别名。
- virtual_server(如果涉及 LVS 控制部分): 用于进一步管理负载均衡,但本笔记主要聚焦在 VRRP 部分。
shell
[root@lb01 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
#全局定义部分
global_defs {
#每个keepalived唯一的表示,不能重复.
router_id lb01
}
#vip配置部分 vrrp实例部分
#vrrp实例名字,1对主备之间名字要统一.
#vip 10.0.0.3
vrrp_instance lb_vip_3 {
#节点 MASTER主节点
#节点 BACKUP备节点
state MASTER
#指定网卡
interface ens33
#id 同1对keepalived 要一致.
virtual_router_id 51
#优先级 主>备 建议相差50
priority 100
#心跳间隔 1s秒发1次. 抓包可以看见
advert_int 1
#认证 主备节点之间的认证,建议保持不变或设置简
单的密码即可.
authentication {
auth_type PASS
auth_pass 1111
}
#virtual_ipaddress vip配置
virtual_ipaddress {
10.0.0.3/24 dev ens33 label
ens33:1
}
}
#lvs配置部分.抓包查看
- 工具使用:
- 当 Wireshark 无法直接使用时,可以利用
tcpdump来抓取 VRRP 数据包。 - 示例命令:
- 当 Wireshark 无法直接使用时,可以利用
plain
tcpdump -vvv -nnn vrrp -w ~/vrrp.pcap- 抓包文件可以后续用 Wireshark 打开,进一步分析 VRRP 的通信情况,验证心跳包是否正常发送与接收。
脑裂现象
脑裂故障(Split Brain)
现象: 主备节点同时拥有 VIP,导致出现脑裂现象。
后果: 脑裂故障不仅会导致系统出现严重的服务冲突,而且会引发数据一致性问题、管理混乱和网络资源浪费,从而对整个业务系统的可用性和可靠性造成较大影响
原因分析:
* 备节点误判主节点状态不正常(可能由于防火墙、selinux 配置、keepalived 配置错误或物理网络故障),从而错误接管 VIP。
监控与解决办法:
* 利用第三方机器(如通过 SSH 执行 `hostname -I` 命令)检查 VIP 是否真正存在于主节点上。
* 也可以设计监控脚本,当检测到备节点错误地接管 VIP时,远程下线主节点以消除脑裂现象。
监控脚本:
shell
#!/bin/bash
# chmod +x force_primary_down.sh
# 文件名: force_primary_down.sh
# 说明: 当备节点错误接管了VIP后,远程触发让主节点停止keepalived,从而避免双端持有VIP(脑裂现象)。
# 注意:需预先配置SSH免密登录,确保备节点可以SSH登录至主节点。
# 定义VIP和主节点信息
VIP="10.0.0.3"
PRIMARY_HOST="10.0.0.3" # 主节点的实际IP地址
SSH_USER="root" # 用于SSH登录的用户名
# 检查本机是否错误接管了VIP
if ip addr | grep -q "$VIP"; then
echo "$(date) - 警告: 本机错误接管 VIP $VIP !"
echo "$(date) - 正在通过 SSH 登录主节点 $PRIMARY_HOST 并停止 Keepalived..."
# 执行远程命令,可以选择停止keepalived或直接关机
# 以下示例为停止 Keepalived 服务
ssh ${SSH_USER}@${PRIMARY_HOST} "systemctl stop keepalived" && \
echo "$(date) - 主节点上的 Keepalived 已停止." || \
echo "$(date) - 无法登录主节点或执行命令,请检查 SSH 和网络设置."
# 如果需要更激进的操作,也可以直接关机:
# ssh ${SSH_USER}@${PRIMARY_HOST} "shutdown -h now"
else
echo "$(date) - 状态正常: 本机未检测到 VIP $VIP 。"
fi基于主机高可用的软件给 Nginx 服务监控
背景:
默认情况下,keepalived 仅在主机挂掉或网络断开时才触发主备切换,并不监控具体的服务状态。
需求:
当某个服务(例如 nginx)停止时,希望 keepalived 能自动进行主备切换。
脚本:
shell
#要有执行权限 chmod +x
# 检查Nginx进程数
proc_cnt=$(ps -ef | grep nginx | grep -v grep | wc -l)
# 获取HTTP状态码(失败时返回000)
http_code=$(curl -L -s -k -w "%{http_code}" -o /dev/null -H "Host: ssl.oldboylinux.cn" https://10.0.0.5/index.html || echo "000")
# 判断条件:进程数为0或状态码非200
if [ "$proc_cnt" -eq 0 ] || [ "$http_code" -ne 200 ]; then
systemctl stop keepalived
fi主节点备节点修改配置文件
shell
[root@lb01 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
# Keepalived 的配置文件,使用 '!' 或 '#' 表示注释行
global_defs {
router_id lb01
# 定义路由器标识符,用于唯一标识本节点
}
# 定义监控脚本,用于检测服务状态
vrrp_script check_ngx.sh {
script /server/scripts/check_ngx.sh
# 指定要执行的脚本路径
interval 2
# 脚本执行的时间间隔,单位为秒
weight 1
# 脚本执行结果对优先级的影响权重,正值表示健康时增加优先级
user root
# 指定执行脚本的用户
}
# 定义第一个 VRRP 实例
vrrp_instance vip_3 {
state MASTER
# 当前节点在该实例中初始状态为 MASTER(主)
interface ens33
# 指定用于 VRRP 通信的网络接口
virtual_router_id 51
# 虚拟路由器的唯一标识符,主备节点必须一致
priority 110
# 当前节点的优先级,数值越大优先级越高
advert_int 1
# VRRP 通告的时间间隔,单位为秒
authentication {
auth_type PASS
auth_pass 1111
# 设置认证类型和密码,用于 VRRP 通信的安全验证
}
virtual_ipaddress {
10.0.0.3 dev ens33 label ens33:1
# 定义虚拟 IP 地址及其绑定的网络接口和标签
}
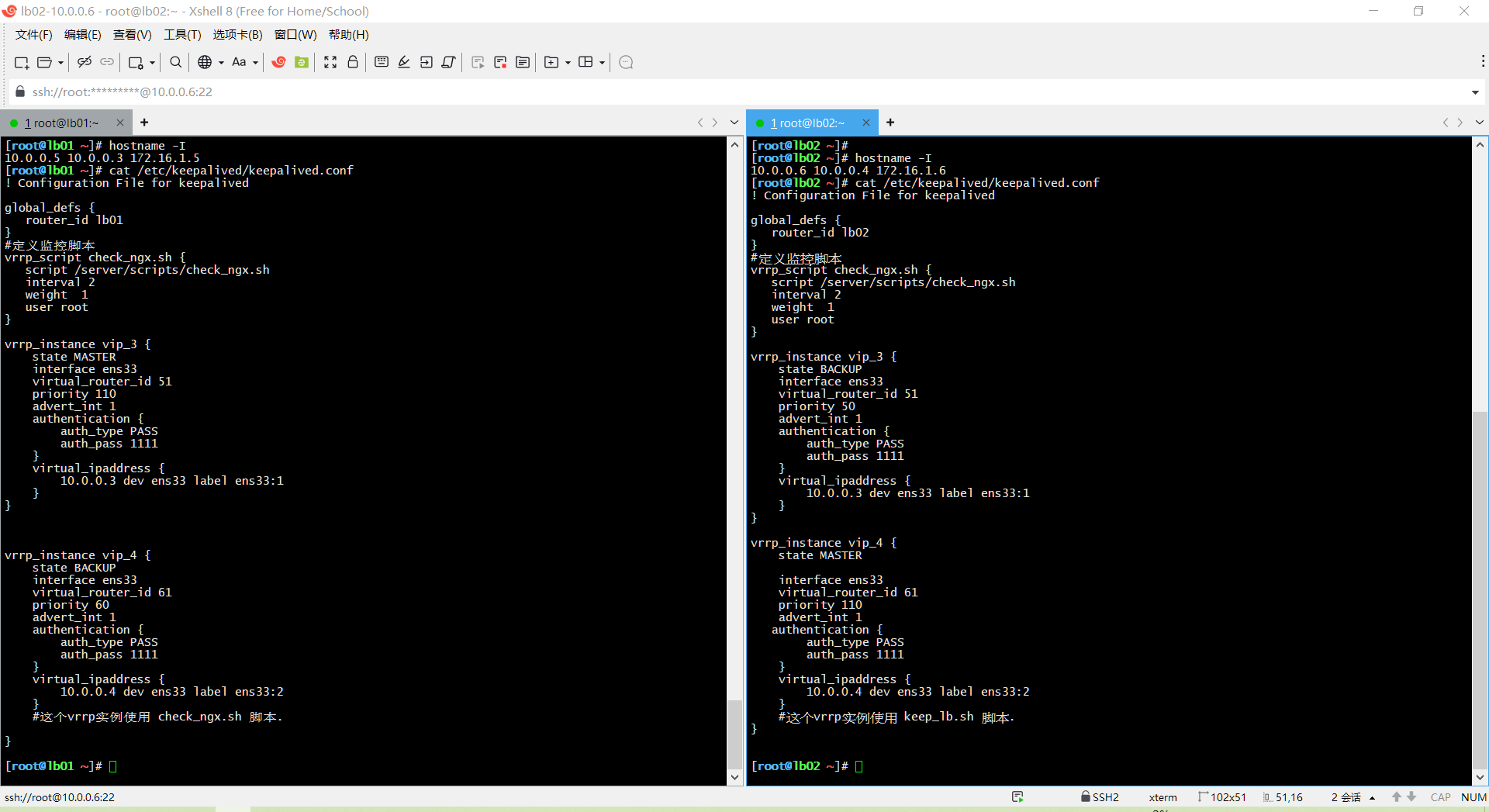
}双主模式(Dual Master Mode):
- 适用于高并发场景,通过拆分域名或流量分发,让两个节点同时处理请求,从而提高整体系统的吞吐能力。
- 在双主模式中,两台服务器都处于活动状态,各自拥有一个虚拟 IP(VIP),并互为对方的备份。每台服务器既是主服务器,又是对方的备份服务器。这样,即使其中一台服务器发生故障,另一台也能接管其 VIP,确保服务的连续性。
shell
[root@lb01 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lb01
}
#定义监控脚本
vrrp_script check_ngx.sh {
script /server/scripts/check_ngx.sh
interval 2
weight 1
user root
}
vrrp_instance vip_3 {
state MASTER
interface ens33
virtual_router_id 51
priority 110
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.3 dev ens33 label ens33:1
}
}
vrrp_instance vip_4 {
state BACKUP
interface ens33
virtual_router_id 61
priority 60
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.4 dev ens33 label ens33:2
}
#这个vrrp实例使用 check_ngx.sh 脚本.
}
################
################
################
[root@lb02 /server/scripts]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lb02
}
#定义监控脚本
vrrp_script check_ngx.sh {
script /server/scripts/check_ngx.sh
interval 2
weight 1
user root
}
vrrp_instance vip_3 {
state BACKUP
interface ens33
virtual_router_id 51
priority 50
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.3 dev ens33 label ens33:1
}
}
vrrp_instance vip_4 {
state MASTER
interface ens33
virtual_router_id 61
priority 110
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.4 dev ens33 label ens33:2
}
#这个vrrp实例使用 keep_lb.sh 脚本.
}
效果
非抢占模式(Non-Preemptive Mode):
- 默认情况下,keepalived 处于抢占模式,即当主节点恢复后,它会自动重新接管 VIP。
- 非抢占模式则阻止这种自动抢回,从而可以让备节点继续承担服务,适合某些特定业务场景的需求。
雪崩现象
负载均衡雪崩现象主要出现在使用负载均衡器的场景中。当集群中某个或多个节点故障或暂时不可用时,负载均衡器将原本分摊到这些节点的流量重定向到其他健康节点上。如果剩余节点承载能力不足,可能瞬间遭受过大流量冲击,从而出现响应延迟、故障扩散甚至整体崩溃,这种连锁反应就称为负载均衡雪崩。
成因
- 节点故障集中重分流:
当集群中的节点突然失效时,负载均衡器会把原本分摊给故障节点的请求转移到其他节点,造成其流量瞬间大幅增加。 - 健康检查不够及时:
如果健康检查机制不够敏感或者配置不合理,故障节点可能仍被部分流量误分配,加剧其他节点的压力。 - 缺乏冗余设计:
当集群节点的数量和能力不足以支撑突增的流量时,就容易引发雪崩效应。
总结
- 核心要点:
- keepalived 是一种基于 VRRP 协议的高可用解决方案,主要用于通过设置 VIP 及节点间的心跳监测来实现服务的自动故障转移。
- 在实际应用中,除了基本的主备切换,还可以利用脚本监控特定服务状态,实现更精细化的故障检测与处理。
- 进阶用法如双主模式和非抢占模式进一步提升了系统在高并发场景下的稳定性和灵活性。